...
Field | Description | |||||||||||||||||
status | A string that specifies the test status. Can be an arbitrary string. Typical values are Passed, OK, Failed, Failure, and so on. For more information, on how Zephyr checks if a test failed or not, see below. | |||||||||||||||||
statusExistPass | An additional indicator of the test status. Can be | |||||||||||||||||
statusString | An expected value for the status field. Zephyr users this field to check if a test failed or not. See below. | |||||||||||||||||
statusFailAttachment | An additional description of test results used when a test failed. Typically, has an extended error message or a call stack for a failed function. Zephyr saves this extended description to a file and then attaches this file to an automation item: 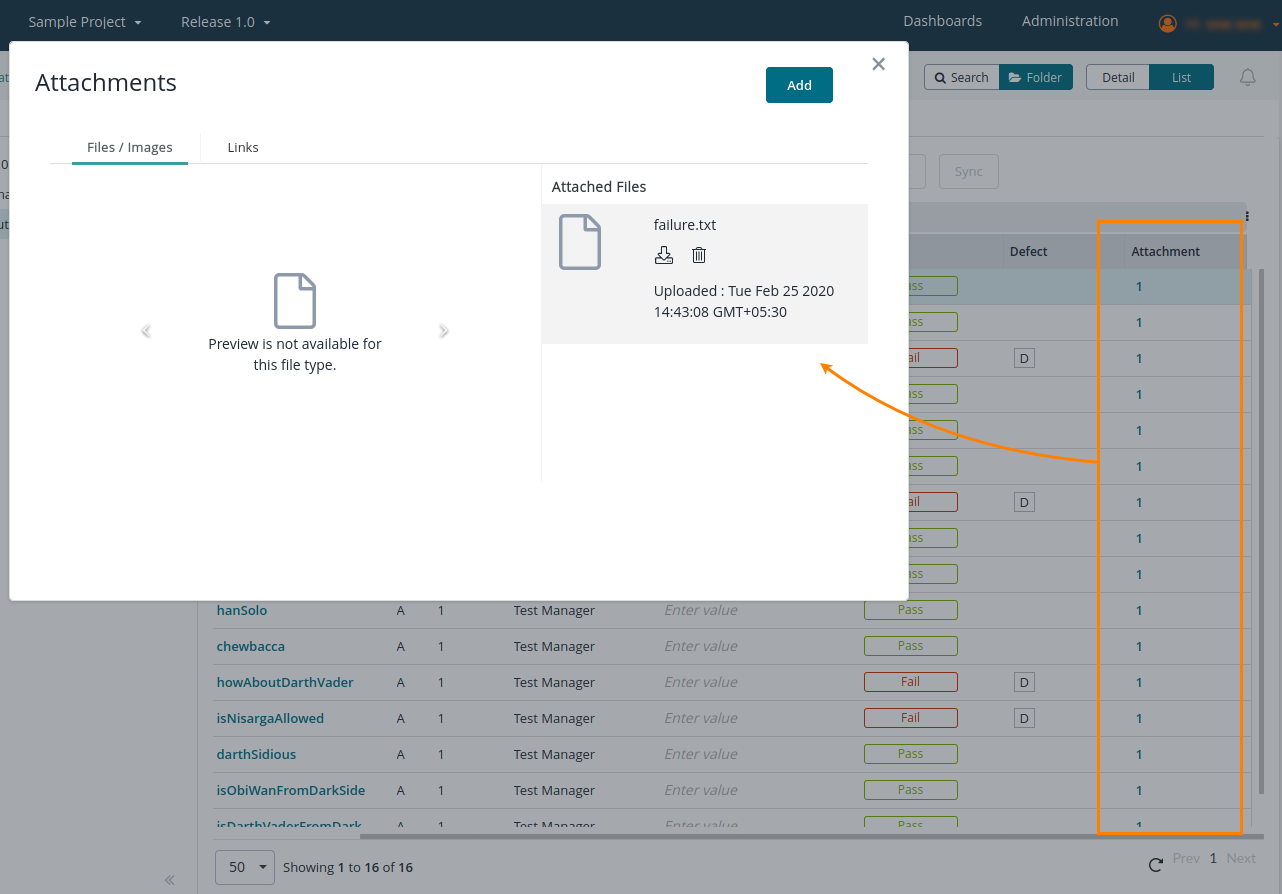 | |||||||||||||||||
statusPassAttachment | An additional description of test results used when a test passed. Typically, has information on the test case name and execution time. Zephyr saves this extended description to a file and then attaches this file to an automation item. See the image above. | |||||||||||||||||
packageName | This property is used only if you commanded Zephyr to create a package-like hierarchy of test execution items. The property specifies the name of the last level in the hierarchy. | |||||||||||||||||
testcase | The name of the executed test case. Will be displayed in the Name column of the Test Execution screen in Zephyr. | |||||||||||||||||
tag | A string of tags set for the test in the test results file. Zephyr pulls these values, parses and adds them to your test case. You will see them in the Tags attribute of the test case. Test results can have one or multiple tags:
Depending on the format of test results, you use different patterns to parse the tag values:
The default parser template has a tag pattern for parsing tags from Cucumber test results. If you use another framework or tool to run your tests, please change the template accordingly. The Tags attribute of a Zephyr test case is limited to 4,000 characters. | |||||||||||||||||
skipTestcaseNames | An XML file can have information on one or multiple test cases. By default, Zephyr will create a test execution item for every test case it finds in the XML file. This field is a string of test case names that which Zephyr will skip and for which it will not create a test run item. The names are case-sensitive. Separate multiple test case names with a comma. Don’t put extra spaces around test case names. | |||||||||||||||||
requirements | An array of requirement IDs or alternative IDs with which a test run is linked. IDs should start with the | |||||||||||||||||
attachments | An array that specifies additional files to be attached to the item. You should specify the path in terms of the computer, where the test ran. The path can be relative or absolute. If you use a relative file name, then it should be relative to the folder, where the test result XML file is located. | |||||||||||||||||
strict | Affects XML node matching with $-expressions. If |
How Zephyr determines if a test failed or passed
...
| Code Block |
|---|
…
"testcase": {
"name": "${testsuite:name}-testsuite.testcase:name}
"
}
… |
Example 2. Include additional data
...
| Code Block | ||
|---|---|---|
| ||
{
"name": "custom-junit",
"jsonTemplate": [
{
"requirements": [
{
"id": "${testsuite.testcase.requirements.requirement}"
}
],
"statuses": [
{
"statusId": "2",
"attachmentText": "${group_concat(testsuite.testcase,failure,'\n')}",
"status": "${group_concat(testsuite.testcase,failure,'\n')}"
},
{
"statusId": "2",
"attachmentText": "${group_concat(testsuite.testcase,error,'\n')}",
"status": "${group_concat(testsuite.testcase,error,'\n')}"
},
{
"default": true,
"statusId": "1",
"attachmentText": "classname: ${testsuite.testcase:classname} name: ${testsuite.testcase:name} time: ${testsuite.testcase:time}"
}
],
"skipTestcaseNames": "",
"packageName": "${testsuite.testcase:classname}",
"testcase": {
"name": "${testsuite.testcase:name}"
},
"attachments": [
{
"filePath": "${testsuite.testcase.attachments.attachment}"
}
]
}
]
} |
Example 4. Using the “strict” option
| Anchor | ||||
|---|---|---|---|---|
|
Suppose, a test case's child nodes include status nodes. You can force the parser ignore them, and thus avoid creating individual test cases for such status nodes while parsing test results. To do that, set the new strict option to true in your parser template: "strict": true. If you use the default value (false), a new test case will be created for each status node on all levels.
| Code Block | ||
|---|---|---|
| ||
{ "jsonTemplate": "[ { \"statuses\":[ { \"statusId\":\"2\",\"attachmentText\":\"Name: ${robot.suite.test:name} \\nResult:${robot.suite.test.status:status} \\nMessage: ${robot.suite.test.status}\",\"status\":\ "${robot.suite.test.status:status}\",\"statusString\":\"FAIL\"},{\"statusId\":\"1\", \"attachmentText\":\"Classname: ${robot.suite:name} \\nTestcaseName: ${robot.suite.test:name} \\nResult: ${robot.suite.test.status:status}\",\"default\":true} ], \"skipTestcaseNames\":\"\",\"packageName\":\"${robot.suite:name}\",\"testcase\":{\"name\": \"${robot.suite.test:name}\" }, \"strict\":true } ]", "name": "robot" } |
| Info |
|---|
For more information on creating parser templates, see Create Parser Templates. |
...
To get the idea of how to perform this or that action, explore the pre-configured preconfigured templates that comes along with Zephyr. See how you can get them.
...